Announcing Gemma 4 on vLLM: Byte for byte, the most capable open models
Elevating Open Models with Advanced Reasoning and Multimodal Capabilities
With the debut of Gemma 4, vLLM introduces immediate support for Google's most sophisticated open model lineup, spanning multiple hardware backends, with first-ever Day 0 support on Google TPUs, AMD GPUs, Intel XPUs. Purpose-built for advanced reasoning and agentic workflows, Gemma 4 delivers an unprecedented level of intelligence-per-parameter, now accessible to the vLLM community under a commercially permissive Apache 2.0 license.
Built from the same world-class research and technology as Gemini 3, the Gemma 4 family includes four versatile sizes designed for diverse hardware environments: Effective 2B (E2B), Effective 4B (E4B), 26B Mixture of Experts (MoE), and 31B Dense.
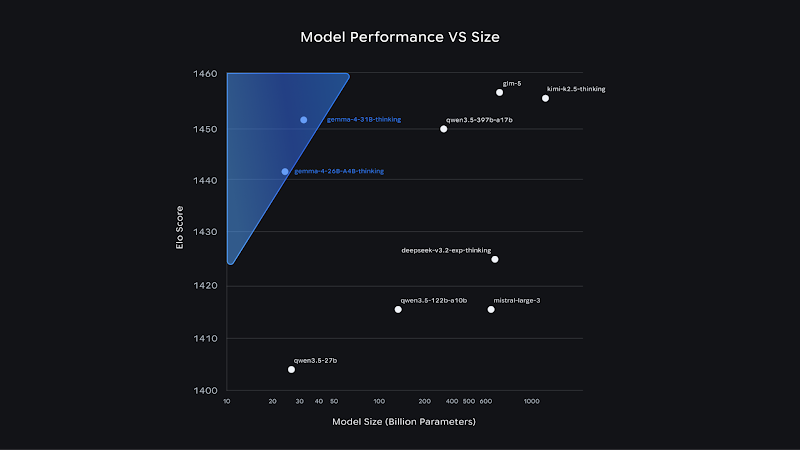
Open model performance vs size on Arena.ai's chat arena as of 2/1. Additional benchmarks in our model card.
Powerful, Accessible, Open
To catalyze the next era of frontier research and product innovation, Gemma 4 models are precisely engineered for efficient execution and fine-tuning across the hardware spectrum—from billions of Android devices to local developer workstations and high-scale accelerators.
By leveraging these highly optimized models, developers can achieve state-of-the-art performance on specialized tasks. Early successes include INSAIT's pioneering Bulgarian-first model, BgGPT, and Yale University's Cell2Sentence-Scale, which utilizes Gemma 4 to identify novel pathways for cancer therapy.
Gemma 4 stands as our most sophisticated open model family to date, defined by the following core capabilities:
- Advanced Reasoning: Capable of complex multi-step planning, Gemma 4 delivers significant breakthroughs in math and logic-heavy instruction-following benchmarks.
- Agentic Workflows: Native support for function-calling, structured JSON, and system instructions enables the construction of reliable autonomous agents capable of tool and API interaction.
- Code Generation: High-quality offline code support transforms any workstation into a powerful, local-first AI development environment.
- Vision and Audio: Models natively process images and video with variable resolution, excelling at OCR and chart understanding. Edge models (E2B/E4B) also include native audio input for speech recognition.
- Longer Context: Process extensive datasets seamlessly with a 128K context window for edge models and up to 256K for larger variants, facilitating repository-level analysis.
- 140+ Languages: Trained natively on over 140 languages, Gemma 4 empowers developers to create inclusive, high-performance applications for a global user base.
Read the Google blog here to learn more about Gemma 4's leading intelligence-per-parameter performance.
Hardware Support
vLLM is optimized to run Gemma 4 across industry-leading hardware backends, enabling developers to achieve frontier-level capabilities with significantly less hardware overhead. vLLM supports seamless deployment on Nvidia, AMD, Intel GPUs and Google TPUs, ranging from laptop-class cards to datacenter accelerators.
Key Capabilities for vLLM Users
- Native Vision and Audio: All models natively process images and video. Smaller edge models (E2B/E4B) also feature native audio input for speech recognition.
- Agentic Workflows: Support for function-calling, structured JSON output, and native system instructions allows vLLM users to build reliable autonomous agents.
- Extended Context: vLLM handles Gemma 4's varying context windows—up to 128K for edge models and 256K for larger models—allowing for long-document and repository-level processing.
- Global Fluency: Natively trained on over 140 languages, enabling inclusive application development.
Getting Started
For technical implementation details, refer to the official model card and community recipes.
To get started with Gemma 4 on Google Kubernetes (GKE) and Google Compute Engine (GCE), check out our quickstart vision and text demo tutorials for Trillium, Ironwood, and Nvidia GPUs.