Extracting hidden states from vLLM
PR #33736 (included in vllm>=v0.18.0) introduced a new hidden states extraction system to vLLM. This blog post explores the motivation, design, usage, and future direction of this feature, and its usage in vLLM’s Speculators (a library for creating and training speculative decoding models).
Motivation
Hidden states are the model's internal intermediate representations of the token sequence. They provide insight into the model’s internal state and are used heavily in speculative decoding.
Speculative Decoding Recap
Speculative decoding typically combines a "verifier" model—the large LLM you are trying to serve—with a small "draft" model. The draft model produces draft tokens that the verifier model then verifies in parallel. This can significantly speed up decoding (up to 2-5x depending on methodology), particularly in lower batch size scenarios, where model performance is memory-bound.
Researchers have found that providing the draft model with internal hidden states from the verifier model can improve drafting alignment and overall quality. Methods like Eagle-3, P-Eagle, DFlash, etc. were therefore designed, which require hidden states from multiple verifier layers as input.
Since the draft models take hidden states as input, training them requires access to a large dataset of hidden states and verifier outputs. Most speculative decoding libraries (like Speculators) solve this using one of two approaches:
- Use
transformersfor hidden states generation. This works but has two major disadvantages: (A) All of vLLM’s performance optimizations like large model/distributed support, etc. are lost. (B) It introduces a whole class of potential bugs caused by minor mismatches between transformer and vLLM hidden states. - Heavy modification and patching of vLLM. This typically requires manually setting up core vLLM components and directly calling internal apis. This results in a large maintenance burden as vLLM internals are updated over time. It also means many vLLM features (such as prefix caching, auto batching, async server, etc.) need to be disabled. This is how previous versions of Speculators (
<0.5.0) handled hidden states generation.
Both approaches have their disadvantages, and as speculative decoding becomes more popular, better more performant solutions are needed.
Design Considerations
There were a number of requirements considered when integrating hidden states extraction directly into vLLM.
To start, the system should return hidden states in a performant way. Model hidden states can be quite large. For a Qwen3-8B model with hidden_size of 4096, the extracted hidden states have a shape [seq_len, num_layers_to_extract, 4096]. For a sequence with 8k tokens, 4 layers, and FP16, this adds up to 268 MB of data. Therefore, serializing the hidden states and returning them directly in the request’s response body is not practical.
And with hidden states taking up so much space, even just temporarily storing them in VRAM is non-trivial. Memory must be pre-allocated, and managed for all the concurrent requests at once, including handling chunked prefill, request preemption, and more to avoid OOM errors.
Since this feature only applies when users need hidden states from vLLM, which is not the case in most deployment scenarios, it’s essential that there is no new overhead (runtime or cognitive) introduced by this feature on vLLM’s “hot path”. In practice, this meant limiting the scope of the changes and re-using existing features wherever possible.
Lastly, there are many different ways the final user may want to use, store, or transfer the hidden states. For example, in “offline” speculator training, hidden states are generated for a full dataset and cached to disk before training begins. “Online” training, on the other hand, generates hidden states on-the-fly during training, and needs the hidden states to be transferred efficiently to each training process, ideally without writing to disk first. To support these different scenarios, the hidden states extraction system needs to be flexible/extensible.
Design Insights
With the above requirements in mind, several design insights led to the implementation of the hidden states extraction system. These insights are summarized below.
- vLLM supports running inference with Eagle-3 (and similar) speculative decoding models, which use verifier model hidden states as input. Therefore, there is already plumbing for moving hidden states from the verifier model into the draft models.
- vLLM has an extensible KV Connector API for efficiently extracting data from vLLM's KV cache, which is used for features like Prefill/Decode Disaggregation. Existing implementations of this API support transferring KV cache data over Nixl, writing it to disk, storing in shared memory, and more. The API is also designed to support async transfers of kv cache states and ensures KV cache blocks aren't freed until transfers are complete.
- Hidden states are mapped to their token sequence inputs in the same way as KV cache data. In other words, for every token there is a hidden state value and the value is only valid in the context of the prefix sequence that comes before it.
- vLLM supports separate KV cache config/sizes for speculative draft models.
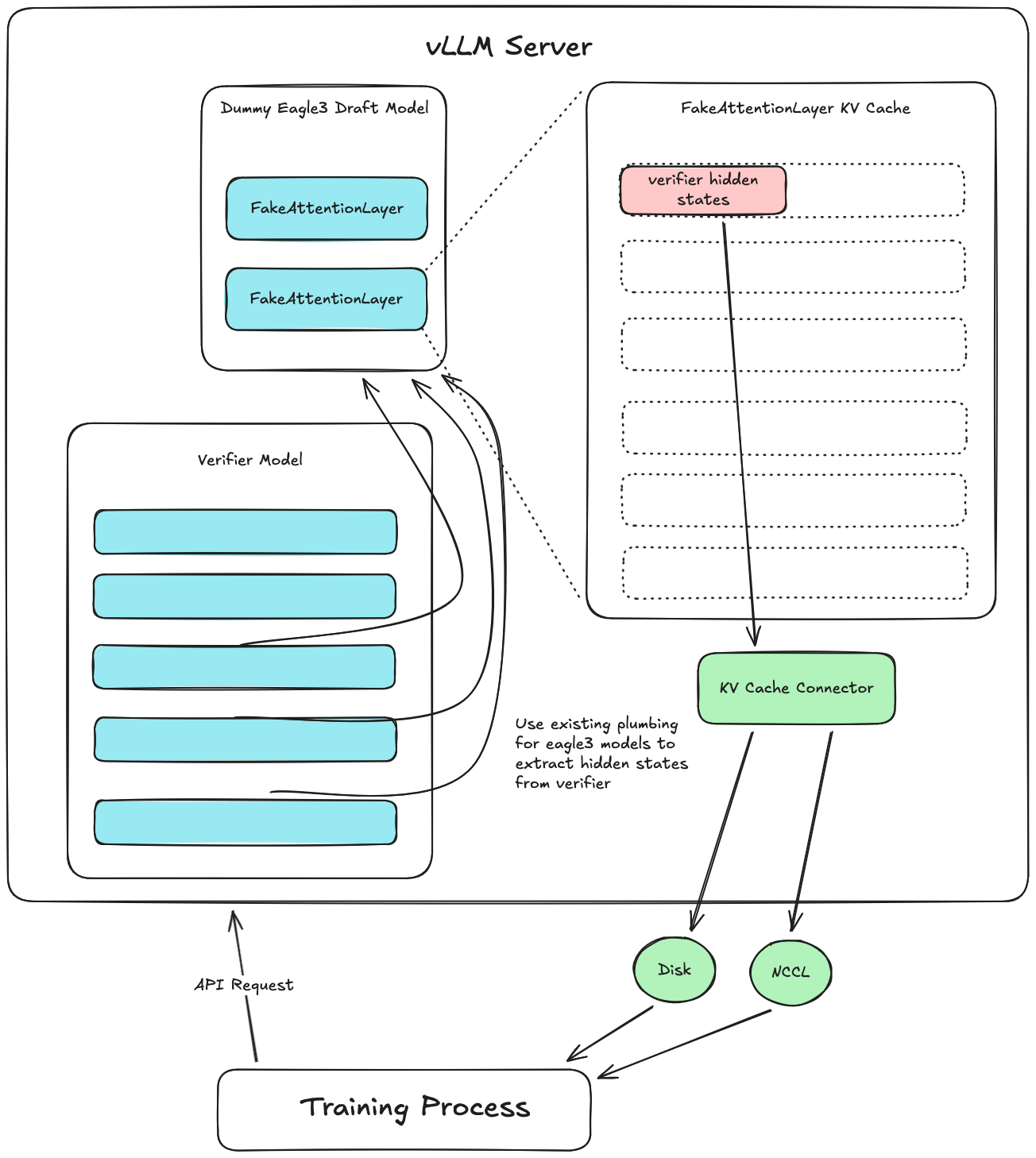
Putting these ideas together (Figure 1), we can extract hidden states by:
- Creating a dummy draft model which receives the verifier hidden states from vLLM using the existing plumbing for Eagle-3 models.
- This dummy model has a dummy attention layer with its own KV cache. Instead of running attention, the dummy model just directly inserts the hidden states inputs into its KV cache.
- Then a custom KV Connector saves the dummy draft model’s KV cache data (which now stores our hidden states) to disk or transfers it some other way.
This meets all design requirements, by utilizing existing Eagle-3 pathways to pipe the hidden states to the draft model and providing a performant method for extracting the hidden states which is flexible enough to handle different downstream usages through the KV Connector API. Since the draft model stores hidden states in dummy attention layers, vLLM knows to allocate VRAM for them. vLLM also manages the hidden states using the same paged memory system as the KV cache uses, which enables prefix caching, chunked prefill, efficient batching, and more.
Usage and Limitations
examples/offline_inference/extract_hidden_states.py shows how to extract hidden states using the Python API. The system also works with the vLLM server and can be launched using the command below.
vllm serve Qwen/Qwen3-8B --speculative_config '{
"method": "extract_hidden_states",
"num_speculative_tokens": 1,
"draft_model_config": {
"hf_config": {
"eagle_aux_hidden_state_layer_ids": [3, 18, 33, 36]
}
}
}' --kv_transfer_config '{
"kv_connector": "ExampleHiddenStatesConnector",
"kv_role": "kv_producer",
"kv_connector_extra_config": {
"shared_storage_path": "/tmp/hidden_states"
}
}'
This command sets up the two major components of the system. The --speculative_config instructs vLLM to use the fake “extract_hidden_states” speculative method, which sets up the dummy draft model. It also supports specifying which layers to extract hidden states from. The second component is the --kv_transfer_config which sets up the custom KV Connector which is designed to just extract the hidden states from the draft models layers. At the time of writing, only the “ExampleHiddenStatesConnector” (a simple implementation that writes to disk) exists, but more performant connectors will be added soon. Please note that these two components must both be used together for the system to work as expected.
Once vLLM is running, any requests to the server will return a "kv_transfer_params" dict which contains a "hidden_states_path". The path points to a saved safetensors file containing the hidden states and token ids. The save directory can be specified via the "shared_storage_path" field in the config above.
# `/tmp/hidden_states/{req_id}.safetensors`
{
"token_ids": [prompt_seq_len],
"hidden_states": [prompt_seq_len, num_hidden_layers, hidden_size]
}
Notes:
- This works with
--tensor-parallel-sizeand--data-parallel-sizearguments for single-node multi-gpu deployments. - Only the prompt tokens and their hidden states will be saved. We therefore recommend calling the
v1/completionsendpoint with amax_tokens=1sampling param.
Ongoing work
- Integration into vLLM's speculators project: The speculators library is designed for efficient training of speculative decoding algorithms. Recently merged speculators PR #353 updated speculators to use the new vLLM native hidden states extraction system, and enabled online training of draft models. This feature will be included in
speculators v0.5.0. - Performance improvements: The initial implementation of a hidden states specific KV Connector (the "ExampleHiddenStatesConnector") isn't yet optimized, and includes blocking hidden states writes. There are active efforts to enable asynchronous writes in this connector.
- Device-to-device connectors: The ExampleHiddenStatesConnector writes hidden states directly to disk, where they can then be utilized by the training process. This approach is simple and provides a good test implementation, but doesn't scale well to larger training loads. Future work will include the development of more advanced hidden states connectors that transfer hidden states directly from one device to another, including in multi-node environments.