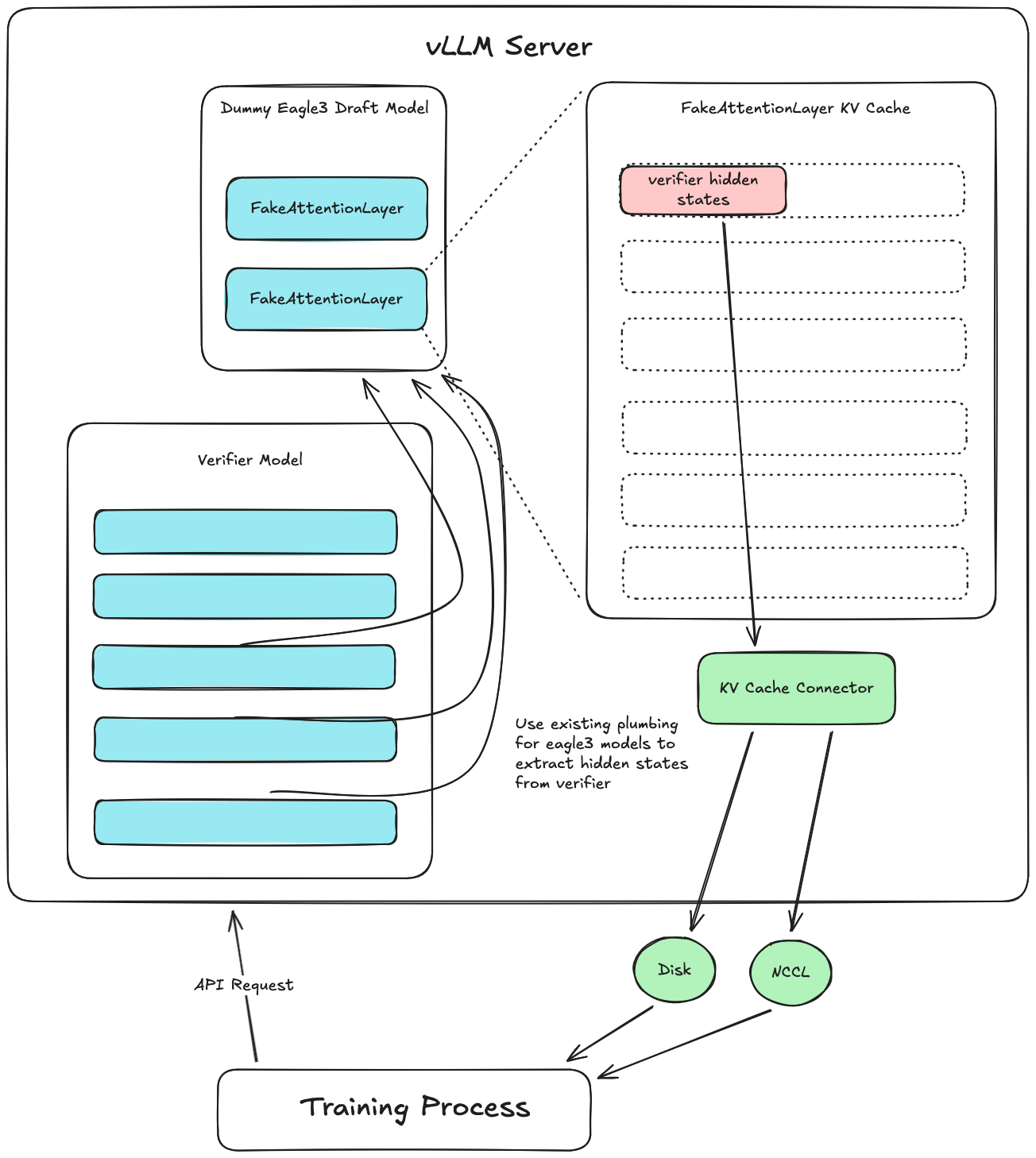
Extracting hidden states from vLLM
·8 min read
PR \#33736 (included in vllm>=v0.18.0) introduced a new hidden states extraction system to vLLM. This blog post explores the motivation, design, usage, and future direction of this feature, and...
5 posts
PR \#33736 (included in vllm>=v0.18.0) introduced a new hidden states extraction system to vLLM. This blog post explores the motivation, design, usage, and future direction of this feature, and...
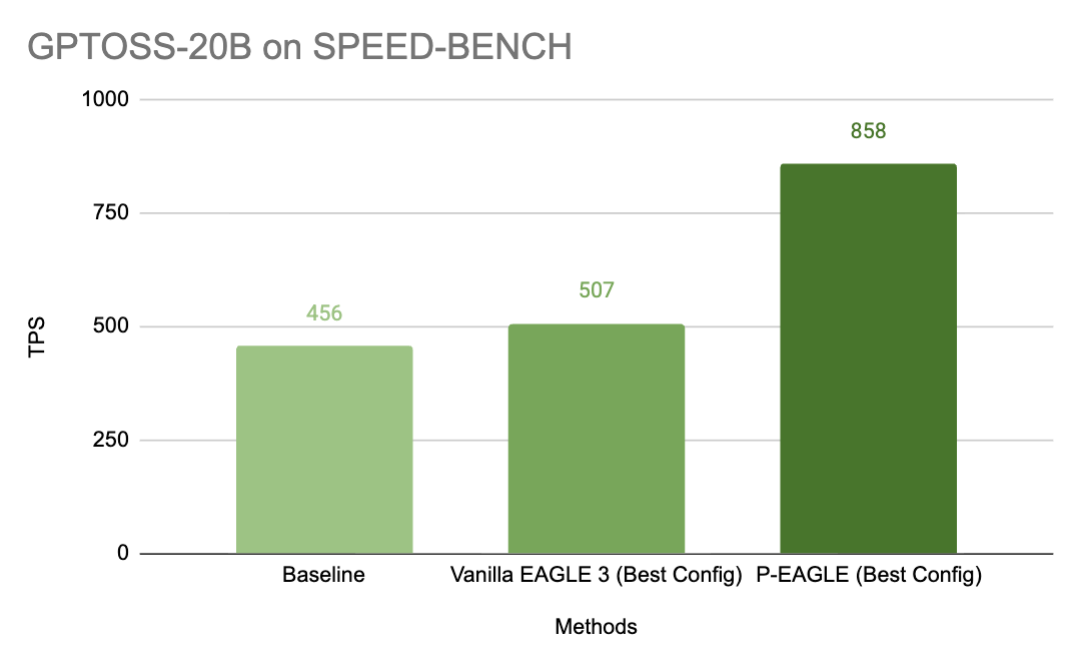
EAGLE is the state-of-the-art method for speculative decoding in large language model (LLM) inference, but its autoregressive drafting creates a hidden bottleneck: the more tokens that you...
- Speculative decoding serves as an optimization to improve inference performance; however, training a unique draft model for each LLM can be difficult and time-consuming, while production-ready...
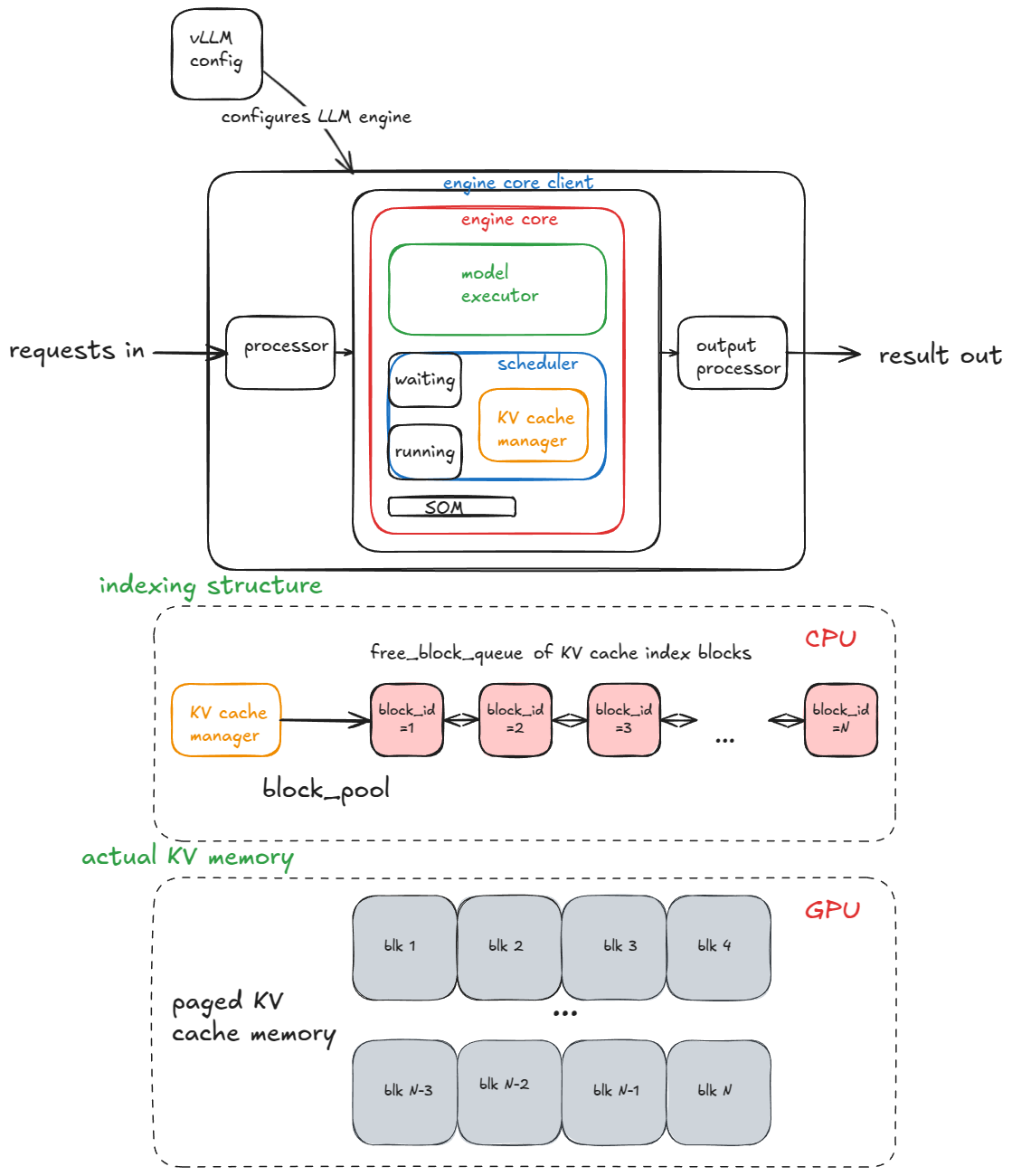
In this post, I'll gradually introduce all of the core system components and advanced features that make up a modern high-throughput LLM inference system. In particular I'll be doing a breakdown...
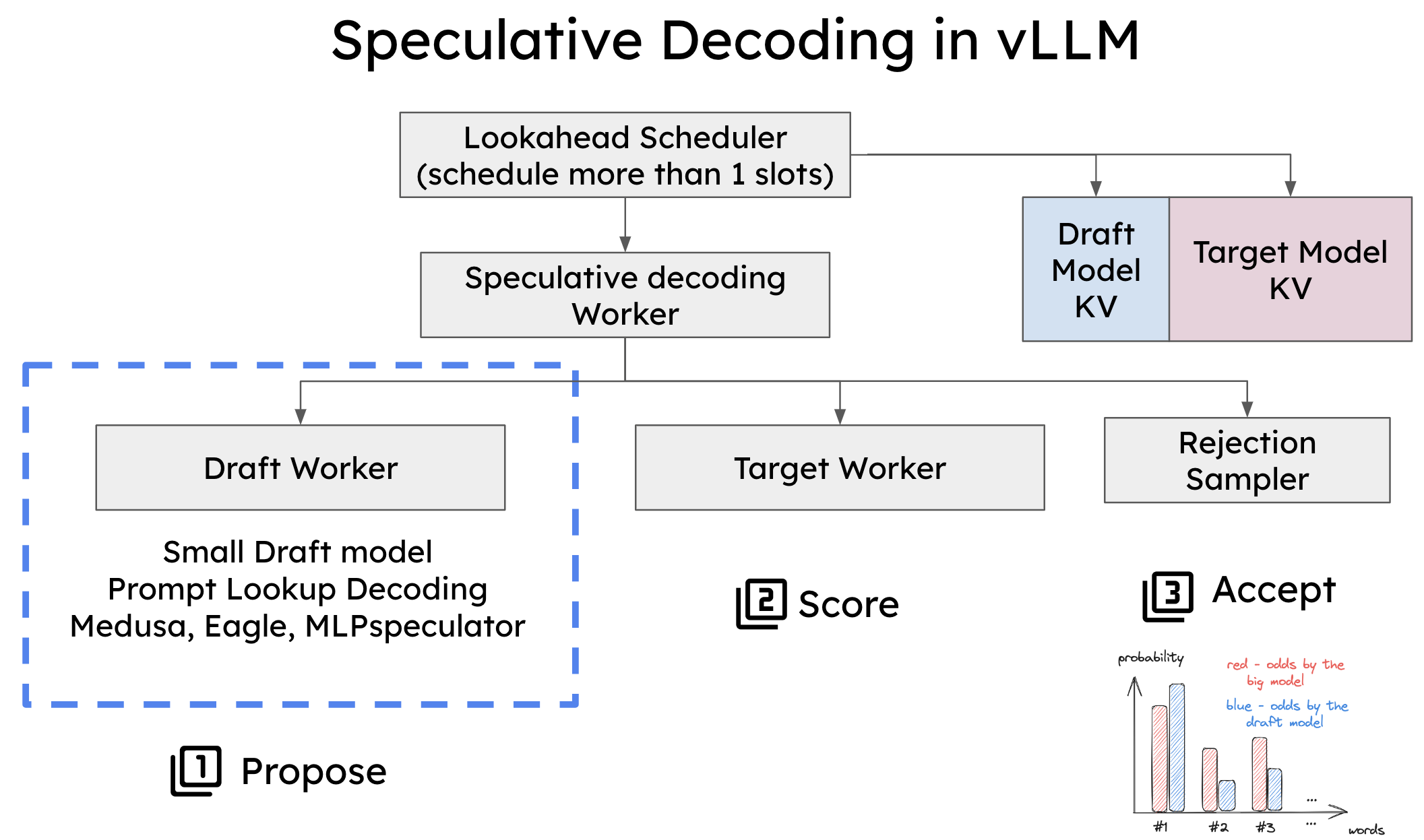
Speculative decoding in vLLM is a powerful technique that accelerates token generation by leveraging both small and large models in tandem. In this blog, we’ll break down speculative decoding in...